
|

| Stats perso, le retour |

|
 |
D epuis que ce site acquit «une certaine notoriété» (c.-à-d., à la fois un certain niveau et un certain type de «notoriété», avec les guillemets nécessaires), il y a environ deux ans, j'ai entamé plusieurs textes à ce propos, mais à chaque fois je n'en étais pas satisfait. Le dernier en date, et seul à figurer encore dans les pages de ce site (peut-être pour peu de temps, d'ailleurs) est son prédécesseur dans la liste de la rubrique «Non documenté», dont le titre est «Je déteste le pape !» (si vous ne l'avez lu, c'était une plaisanterie à propos du fait [réel] que la mort de J.-P. bis fit brutalement chuter la fréquentation de ce site pendant quelques jours…). Le problème vient de ce que je me perds très vite en détails inutiles pour étayer mon propos, alors que ça n'a pas tant d'importance que je le pense, au fond. Le propos est: la vraie notoriété s'acquiert par l'approbation publique d'une personne ou d'un groupe ayant de la notoriété. On peut considérer que le site où vous lisez cette page (si du moins vous la lisez là où je l'ai publiée) a «de la notoriété», du moins en France: si par exemple vous entrez “bateson” dans la zone de saisie du moteur de recherche google.fr, il apparaît en deuxième dans la liste (avec google.com c'est moins glorieux: il n'apparaît pas parmi les 826 pages proposées parmi plus de 1,5 millions [incidemment, pourquoi ce choix aussi limité ?]. Pour qu'il figure sur ce site il faut taper l'ensemble “gregory bateson ecologie esprit” – sans les guillemets – et il y vient en 146° position, en ce 12 mars 2006, et après de multiples sites rédigés dans des langues «états-uniennes»: anglais, espagnol, italien. D'ailleurs, le moteur me demande si je n'ai pas fait une erreur de saisie et propose obligeamment de corriger “écologie” par “ecology”. Mais non pas “esprit” par “spirit” ou “mind”…).
Donc, une certaine notoriété. Si, passant par une des pages d'accueil, vous avez remarqué le compteur qui figure en bas de la page (bien qu'il soit assez discret, car je ne déteste rien tant que ces sites prétentieux qui vous balancent un gros compteur tout en au de leurs pages, genre:
Il y a eu visiteurs sur ce site ! Félicitations ! |
Le fait est qu'au lieu du compteur actuel (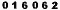 )
j'aurais pu prendre encore plus discret:
)
j'aurais pu prendre encore plus discret: 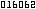 . Mais il
faut tout de même que je puisse le lire sans me coller à l'écran…. Vous aurez donc
peut-être remarqué ce compteur, installé le 15 août 2003. Il reflète mal la progression
de sa fréquentation et le nombre réel de visiteurs. Ce site contient quelques 1800 pages
(dont environ 300 de mon visites entre le
15/08/2003 et le 12/03/2006, ça fait «en moyenne» 17 visites par jour; or, au 12 décembre
2004 il y eut 4.000 visites, soit environ 8 par jour; on passe à 8.000 visites vers le 15
juin 2005, ce qui fait monter la moyenne pour cette période à plus de 22 visiteurs par
jour; le doublement suivant (16.000 visites) a eu lieu le 11 mars 2006, ce qui donne pour
cette troisième période une moyenne de 59 visites par jours. Quant à l'autre point,
l'outil statistique que met mon prestataire Internet indique un tout autre niveau: pour
la période allant de mars 2005 à février 2006, cet outil m'a compté 150.752 visites, soit
9,5 fois plus sur un an que pour les quelques trois ans et demi de mise en place du
compteur. Voici un petit tableau recensant la progression du site au cours des derniers
douze mois, à la date où j'écris:
. Mais il
faut tout de même que je puisse le lire sans me coller à l'écran…. Vous aurez donc
peut-être remarqué ce compteur, installé le 15 août 2003. Il reflète mal la progression
de sa fréquentation et le nombre réel de visiteurs. Ce site contient quelques 1800 pages
(dont environ 300 de mon visites entre le
15/08/2003 et le 12/03/2006, ça fait «en moyenne» 17 visites par jour; or, au 12 décembre
2004 il y eut 4.000 visites, soit environ 8 par jour; on passe à 8.000 visites vers le 15
juin 2005, ce qui fait monter la moyenne pour cette période à plus de 22 visiteurs par
jour; le doublement suivant (16.000 visites) a eu lieu le 11 mars 2006, ce qui donne pour
cette troisième période une moyenne de 59 visites par jours. Quant à l'autre point,
l'outil statistique que met mon prestataire Internet indique un tout autre niveau: pour
la période allant de mars 2005 à février 2006, cet outil m'a compté 150.752 visites, soit
9,5 fois plus sur un an que pour les quelques trois ans et demi de mise en place du
compteur. Voici un petit tableau recensant la progression du site au cours des derniers
douze mois, à la date où j'écris:
Visites
| Moyenne | Total
| 2005 | Mars | 423 | 13.132
| | Avril | 420 | 12.602
| Mai | 443 | 13.756
| Juin | 345 | 8.633
| Juillet | 276 | 6.901
| Août | 274 | 8.231
| Septembre | 305 | 8.858
| Octobre | 427 | 13.259
| Novembre | 550 | 16.526
| Décembre | 500 | 15.508
| 2006 | Janvier | 525 | 16.288
| | Février | 609 | 17.058
| Total | 441 | 150.752
| | ||||
Qui aurait eu l'idée de vérifier que la «moyenne totale» de visites correspond à la moyenne mois à mois aurait vu un certain écart (la moyenne donnée par ce tableau donne normalement une moyenne générale de 413 visites / jour); c'est que, pour des raisons que j'ignore, 23 jours ont «sauté» (pas de stats pour ces journées), ce qui explique la différence: la moyenne porte sur 342 jours, et non sur 365.
Voilà-t-il pas que je retombe dans mon travers: faire des tableaux, balancer des nombres, pour «donner du poids» à mon discours ! Inutile… Revenons-y donc, à ce discours. Je tiens cependant à préciser avant ça pourquoi je décortique ces données: montrer que je ne raconte pas n'importe quoi sur la prémisse de départ, «ce site a une certaine notoriété». Et même, «de plus en plus de notoriété» (les statistiques pour les huit premiers jours de ce mois de mars indiquent une moyenne de plus de 800 visites par jour). Mais, quelle notoriété ? Pour l'heure, le type de «notoriété» que peut avoir un point de vue (un «site»…) pittoresque sur le bord de la route. Les internautes empruntent les «autoroutes de l'information», ou ses nationales, ou ses départementales, ou ses vicinales, et de temps à autres, passent devant ce site-ci. Certains ne font que passer devant sans même le remarquer, certains y jettent un œil rapide, certains encore le regardent d'un peu plus près, quelques rares s'y arrêtent et de plus rares encore s'y promènent. Enfin, une poignée l'explore, le trouve attrayant ou intéressant, et y revient régulièrement. Si on met en regard le nombre de visites et le nombre de pages accédées, on s'aperçoit alors qu'une grande majorité des visiteurs ne consulte au plus deux pages:
| Moyennes | Totaux
| Hits | Pages | Visites
| Sites | Visites | Pages
| 2005 | Mars | 2.708 | 766 | 423 | 9.711 | 13.132 | 23.753
| | Avril | 2.646 | 778 | 420 | 9.704 | 12.602 | 23.357
| Mai | 3.118 | 734 | 443 | 10.849 | 13.756 | 22.758
| Juin | 2.504 | 611 | 345 | 7.372 | 8.633 | 15.289
| Juillet | 1.797 | 496 | 276 | 5.127 | 6.901 | 12.412
| Août | 1.758 | 519 | 274 | 5.571 | 8.231 | 15.576
| Septembre | 2.019 | 549 | 305 | 6.381 | 8.858 | 15.924
| Octobre | 3.034 | 816 | 427 | 8.886 | 13.259 | 25.323
| Novembre | 3.873 | 1.096 | 550 | 11.255 | 16.526 | 32.887
| Décembre | 6.733 | 4.492 | 500 | 9.770 | 15.508 | 139.275
| 2006 | Janvier | 2.722 | 841 | 525 | 9.752 | 16.288 | 26.097
| | Février | 3.180 | 1.089 | 609 | 9.908 | 17.058 | 30.511
| | ||||||
Le nombre moyen de pages par visite est d'exactement 2,5. Sans vous assommer avec des données détaillées, du moins cette moyenne est aussi fausse que les autres: en général le ratio de pages par visites est autour de 1,5 mais certains jours il est très au-dessus. Pour exemple, le mois de février:
Statistiques journalières, Fevrier 2006
| Jour | Hits | Pages
| Visites | Sites | Ratio
| 1 | 2.895 | 1.417
| 401 | 459 | 3,53
| 2 | 1.531 | 372
| 277 | 317 | 1,34
| 3 | 2.780 | 773
| 445 | 440 | 1,74
| 4 | 2.199 | 652
| 429 | 429 | 1,52
| 5 | 2.295 | 607
| 418 | 424 | 1,45
| 6 | 3.597 | 1.360
| 568 | 569 | 2,39
| 7 | 3.162 | 855
| 638 | 609 | 1,34
| 8 | 3.268 | 1.047
| 675 | 655 | 1,55
| 9 | 2.900 | 798
| 609 | 605 | 1,31
| 10 | 2.934 | 905
| 530 | 519 | 1,71
| 11 | 4.495 | 2.101
| 442 | 418 | 4,75
| 12 | 2.866 | 925
| 645 | 535 | 1,43
| 13 | 2.914 | 863
| 583 | 567 | 1,48
| 14 | 2.989 | 906
| 623 | 598 | 1,45
| 15 | 3.346 | 1.045
| 665 | 628 | 1,57
| 16 | 4.727 | 2.104
| 633 | 616 | 3,32
| 17 | 3.555 | 1.044
| 615 | 583 | 1,70
| 18 | 2.669 | 903
| 482 | 469 | 1,87
| 19 | 3.112 | 818
| 563 | 548 | 1,45
| 20 | 2.915 | 817
| 590 | 566 | 1,38
| 21 | 2.987 | 885
| 635 | 596 | 1,39
| 22 | 3.770 | 1.217
| 772 | 670 | 1,58
| 23 | 4.478 | 2.052
| 816 | 728 | 2,51
| 24 | 3.366 | 1.127
| 835 | 670 | 1,35
| 25 | 2.914 | 1.145
| 750 | 646 | 1,53
| 26 | 3.788 | 1.552
| 796 | 717 | 1,95
| 27 | 3.397 | 1.023
| 744 | 697 | 1,38
| 28 | 3.207 | 1.198
| 887 | 755 | 1,35
| | Moyenne | 1,83
| Minimum | 1,31
| Maximum | 4,75
| | ||||||||||
Sur les 28 jours de février, seuls 4 ont un ratio nettement au-dessus de la moyenne (au-delà de 50%) mais la moyenne de ces 4 jours est presque double de celle générale (3,53 contre 1,83). Il faut alors considérer, non que les internautes changent leurs habitudes une fois par semaine mais que ces jours-là une personne ou deux, intéressées par le site, font «monter la moyenne» en explorant beaucoup plus de pages que le visiteur ordinaire qui, pour son compte, en visite une à trois. Ce que confirme le fait que, pour deux des jours «anormaux», le nombre de visites est assez en-dessous de la moyenne (401 et 442 pour une moyenne de 602). Bien sûr, je ne me contente pas de ce genre de confirmations: de fait je constate une forte corrélation entre les jours de plus haute moyenne et les messages de visiteurs me félicitant de la grande qualité du site ou de son éminent intérêt, et me promettant (ou se promettant) d'y revenir régulièrement et de m'écrire pour en discuter. Ce qui ne se passe généralement pas. Enfin, pour la seconde partie de la proposition: m'écrire et faire des commentaires; pour la première, y revenir régulièrement, je n'en sais rien mais j'imagine que c'est rare, somme toute.
C'est que, il y a des centaines de millions de sites, dont des centaines de milliers d'un certain intérêt ou d'un intérêt certain; même l'internaute le plus constant, le plus féru et le plus curieux n'explorera guère, qu'une ou deux centaines de sites chaque jour, et parmi eux un bon nombre de nouveaux sites. Si je considère ma propre manière d'user d'Internet, je dirai que je visite moins de dix sites très régulièrement (plusieurs fois par semaine), une grosse vingtaine assez régulièrement (moins de dix fois par mois), irrégulièrement (moins de dix fois par trimestre) une cinquantaine, et pour les autres, c'est au petit bonheur la chance. Même pour les sites dont je me suis promis, considérant leur intérêt, d'y revenir régulièrement. Je parle bien sûr des sites «à contenu», pour ceux d'usage (sites de téléchargement par exemple) j'y retourne souvent, mais on ne peut strictement dire que je les «visite»: je cherche un utilitaire quelconque, lance une recherche dans un «moteur» idoine qui me trouve des pages là-dessus, j'y accède, regarde brièvement s'il s'y trouve ce que je cherche, si oui, récupère la chose, et puis voilà. De là à dire que je «visite» des sites comme "zdnet.fr" ou "clubic.com" il y a une sacrée marge ! En fait, je crois bien (plutôt, j'en suis sûr) n'avoir jamais vu la page d'accueil de ces deux sites…
Malgré tout il existe un site que je fréquente assidûment, régulièrement, abondamment, bref, un nombre conséquent de fois par semaine et même, très souvent, un grand nombre de fois par jour: "google.fr". Pour d'autres ce sera "yahoo.fr" ou "altavista.fr"; disons: les sites les plus visités sont des «non sites», presque sans contenu propre, les moteurs de recherche.
Le type de notoriété qu'a obtenu ce site est précisément lié à la manière dont lesdits «moteurs» fonctionnent: voler au secours du succès. Le seul à l'expliquer clairement est Google, mais par fatalité les autres, du moins les plus anciens, doivent procéder très largement d'une manière similaire. C'est que, si vous faites une recherche du genre
Sauf cas particulier comme le projet de bibliothèque virtuelle lancé par l'Europe sur initiative de la France, qui ne concernera qu'une infime partie des pages Internet, un classement qualitatif, requerrait une évaluation active des pages par les visiteurs même; il est inenvisageable qu'une structure limitée, serait-elle de la taille de Microsoft ou IBM, fasse seule le travail: actuellement,Google recense plus de huit milliards de pages ! En consacrant en moyenne cinq minutes pour chacune (la lire, l'évaluer, la classer, la décrire), et si 100.000 personnes consacraient 8 heures par jour, 5 jours par semaines, 47 semaines par an à ce travail, il faudrait trois ans et demi «en l'état»; au rythme où vont les choses il y aura alors deux ou trois fois plus de pages: en décembre 2003, trois ans et demi après sa création, Google ne recensait «que» 3,3 milliards de pages; deux ans et demi plus tard leur nombre a plus que doublé; la multiplication actuelle des sites personnels et surtout des “blogs”, l'augmentation d'abonnés à Internet et la généralisation de la connexion haut débit illimité laissent prévoir un nouveau doublement dans environ deux ans. Imaginez qu'un site comme lemonde.fr ou liberation.fr crée à lui seul plusieurs milliers de pages chaque jour. Cela sans compter les évolutions récentes (dont le développement du partage de fichier, le “peer to peer”) qui laissent prévoir sous peu de temps l'accès au contenu partagé de tout ordinateur connecté sur le réseau mondial; cela fera «exploser» (comme on dit dans le jargon médiatique) le nombre de documents disponibles. Non pas nouveaux mais disponibles.
Mais bien des pages sont déjà de simples duplications de pages ou ont un contenu similaire; pour exemple, j'ai remarqué que beaucoup de pages de l'encyclopédie en ligne “Wikipedia” sont reproduites telles que quatre, cinq, six fois ou plus, et leurs contenus intégrés à au moins autant de pages «nouvelles». Pour reprendre le cas de “+descartes +discours +méthode”, outre que nombre de références (dont celles vers ce site même) renvoient à une publication en ligne du texte en question, on constate vite que les mêmes pages de commentaires ou d'anecdotes (biographie, “histoire du siècle”, etc.) existent en plusieurs exemplaires, parfois sur le même site, tantôt sous plusieurs formes (page html, fichier de traitement de texte, document PDF), tantôt sous une seule.
Les moteurs de recherche n'ont pas de subtilité: quel que soit leur mode de classement des pages proposées, du moins, sauf dans le cas (qui commence à apparaître, mais j'en reparlerai peut-être plus loin) d'une indexation sélective et qualitative, le mode de collectage ne peut qu'être formel, avec le correctif possible de ce qu'on appelle, pour les pages html et les documents usant d'indicateurs similaires, les «métainformations» (nom d'auteur, descriptif, mots-clés, éditeur, catégorie, résumé…). Cela signifie que, pour reprendre mon exemple sur Descartes et son discours, toutes les pages contenant ces termes seront recensées, leur classement dans la liste générée ne dépendant pas de la pertinence propre de ces pages. En fait, il faudrait un classement hiérarchique, comme on peut en voir sur certains sites spécialisés où justement est fait le travail indiqué: les pages sont proposées par leurs auteurs, évaluées par les personnes qui collaborent avec le site, puis classées par secteurs (et sous-secteurs), catégories (et sous-catégories), genres (et sous-genres). Le visiteur a aussi, le plus souvent, l'opportunité de passer ce classement en lançant une recherche simple (chercher un contenu) ou plus complexe (faire une recherche sélective). Un bon exemple, parmi bien d'autres, de cette approche, est le site “sourceforge.net”, où l'arborescence est à trois niveaux (ce qui suffit largement pour les 130.588 éléments répartis en 19 rubriques: si le nombre moyen de sous-rubriques est d'environ 20, au troisième niveau le nombre moyen d'éléments sera d'environ 350, loin des parfois plusieurs millions de propositions de Google). Outre cela, on peut faire une recherche libre où filtrer sa recherche par «environnement de base de données», par «statut de développement» (de “en projet” à “fonctionnel”), par public visé (usager, développeur, etc.), par licence (freeware, shareware, commercial, sous GLP, copyright, copyleft, etc.), par système d'exploitation, par langage de programmation; on peut aussi filtrer par langues supportées ou par type d'interface (“ligne de commande”, texte, semi-graphique, graphique, etc.).
Mais une telle approche ne vaut que pour un nombre relativement restreint d'éléments, quelques centaines de milliers, au maximum un ou deux millions; au-delà, on se retrouve rapidement dans le cas indiqué plus haut: le temps nécessaire pour maintenir une telle structure devient vite rédhibitoire.
[1] À entendre comme: dont je suis l'auteur au plan du contenu; il est évident que, ce ce site étant réellement personnel au sens où, étant son unique mainteneur, je suis auteur de toutes les pages qu'il contient en tant que je les ai moi-même créées et mises en ligne. Cela dit, d'un côté cette notion est délicate: pour les textes de ma main, je ne m'en sens pas autant l'auteur que ça car ce qui m'a permis de les écrire est toute la culture acquise en lisant ou écoutant mes semblables, mais en sens inverse cet objet unique, «le site OMH», j'en suis l'auteur intégral car il reflète un choix particulier, celui de son mainteneur. Disons pour être exact que sur les quelques 1.800 pages que contient ce site, celles qui furent composées et mises en ligne pour la première fois et avec un contenu inédit sont au nombre de 300 environ. Mais Internet étant ce qu'il est, plusieurs de ces pages existent désormais par ailleurs, parfois sans indication d'origine, et leur inclusion dans un ensemble autre fait que leur(s) auteur(s) est (sont) le(s) mainteneur(s) de ces sites.